基于fastText对商品评论进行情感分析
1.问题背景
在电商平台中,很多用户都会基于自己的购物体验对商品进行评分和评论.但有些用户只给出了评论而没有评分,没有了评分的量化标准,这给商家进行数据运营与选品决策带来了困难.如何根据商品评论估计出相对应的评分,这是情感分析的问题,我们可以用fastText文本分类器来快速解决.
2. fastText简介
fastText是FAIR(Facebook AI Research)于2016年开源的一个词向量与文本分类工具,主要优点是能够取得与深度神经网络相媲美的分类精度,同时训练速度比深度神经网络快几个数量级,节约了不小的训练成本,果然是名副其实fastText.
3. fastText安装
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ sudo python setup.py install
4. 准备数据
Yelp是美国著名商户点评网站,提供了470万的用户评论数据以作科学研究.Yelp采用的是五星级评分,用户评分和评论的例子如下:
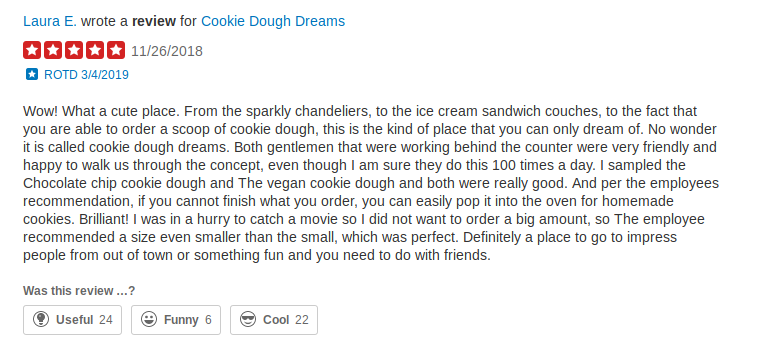
下载解压后会得到数据reviews.json(大约5.3G),每行是个json对象,格式如下:
{
"review_id": "abc123",
"user_id": "xyz123",
"business_id": "1234",
"stars": 5,
"date":" 2019-01-01",
"text": "This restaurant is great!",
"useful":0,
"funny":0,
"cool":0
}
但是fastText要求输入的数据需要有个标签前缀__label__YOURLABEL,所以我们要对reviews.json的数据进行预处理,像上面的评论要转换为
__label__5 This restaurant is great!
5. 数据预处理
import json
from pathlib import Path
import re
import random
reviews_data = Path("yelp_dataset") / "yelp_academic_dataset_review.json"
training_data = Path("fasttext_dataset_training.txt")
test_data = Path("fasttext_dataset_test.txt")
# 按照9:1比例随机划分的训练数据和测试数据,percent_test_data为测试集对总数据集的占比
percent_test_data = 0.10
def strip_formatting(string):
string = string.lower()
string = re.sub(r"([.!?,'/()])", r" \1 ", string)
return string
with reviews_data.open() as input, \
training_data.open("w") as train_output, \
test_data.open("w") as test_output:
for line in input:
review_data = json.loads(line)
rating = review_data['stars']
text = review_data['text'].replace("\n", " ")
text = strip_formatting(text)
fasttext_line = "__label__{} {}".format(rating, text)
if random.random() <= percent_test_data:
test_output.write(fasttext_line + "\n")
else:
train_output.write(fasttext_line + "\n")
将上面代码保存为dataPre.py,运行后会得到按照9:1比例随机划分的训练数据和测试数据(fasttext_dataset_training.txt & fasttext_dataset_test.txt)
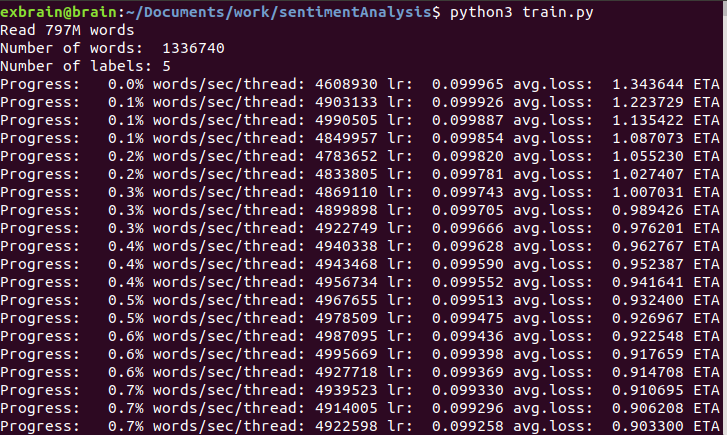
6. 训练模型
import fasttext
model = fasttext.train_supervised(input="fasttext_dataset_training.txt")
model.save_model("model_reviews.bin
")
训练模型并保存模型为model_reviews.bin
7. 测试模型
import fasttext
def print_results(N, p, r):
print("样本数N\t" + str(N))
print("精确率P@{}\t{:.3f}".format(1, p))
print("召回率R@{}\t{:.3f}".format(1, r))
model = fasttext.load_model("model_reviews.bin")
print_results(*model.test('fasttext_dataset_test.txt'))

运行后得到测试结果精确率是69.6%,还是有很大的提升空间的:joy:
8. 优化模型
在之前的模型训练中是不考虑单词的顺序的,每个单词在句子中是独立的,但实际情形不是这样的,往往需要考虑上下文,这个时候我们可以用参数wordNgrams来进行改进,把N个单词捆绑在一起进行训练.考虑到时间成本,我们取wordNgrams=2
import fasttext
model = fasttext.train_supervised(input="fasttext_dataset_training.txt", lr=0.8, epoch=25, wordNgrams=2)
model.save_model("model_reviews.bin")
def print_results(N, p, r):
print("样本数N\t" + str(N))
print("精确率P@{}\t{:.3f}".format(1, p))
print("召回率R@{}\t{:.3f}".format(1, r))
print_results(*model.test('fasttext_dataset_test.txt'))
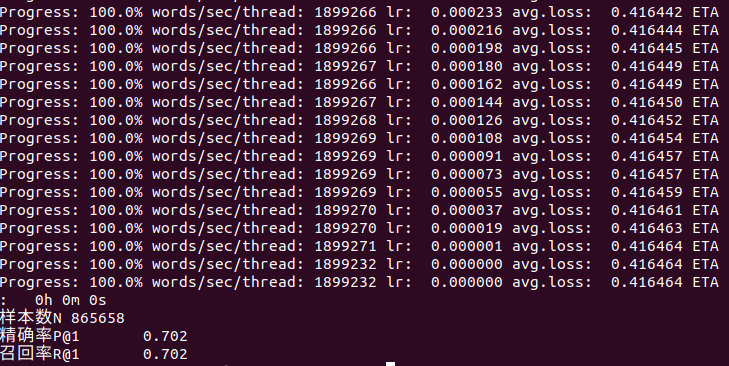
精确率为70.2%,只提高了0.6%,模型仍需要优化啊
我们随机找几个评论预测一下星级评分
import fasttext
model = fasttext.load_model("model_reviews.bin")
sent = input("Please input:")
test = model.predict(sent)
s = float('%.4f' % test[1])
if test[0] =="('__label__1.0',)":
print("Star rating:☆ \nConfidence: % s%%" % (s*100))
elif test[0] =="('__label__2.0',)":
print("star rating:☆☆ \nConfidence: % s%%" % (s*100))
elif test[0] =="('__label__3.0',)":
print("star rating:☆☆☆ \nConfidence: % s%%" % (s*100))
elif test[0] =="('__label__4.0',)":
print("star rating:☆☆☆☆ \nConfidence: % s%%" % (s*100))
else:
print("star rating:☆☆☆☆☆ \nConfidence: % s%%" % (s*100))
