在Neo4j中将图片加到节点中
1.问题背景
这个需求是由Eve同学提出来的,问我能不能在Neo4j中嵌入图片。我试了下用本地图片去创建节点,可是失败了,然后就在neo4j中文版导入图片的路径问题看到图片不能用文件路径
于是就通过图床将本地图片转化为url的图片路径
再创建节点导入图片发现图片url地址是可以存在数据库中但是查看不给你显示图片出来,这就有些尴尬了不美观
尝试在Neo4j基础上找到可视化工具进行渲染,比如有neo4jd3,效果挺动态酷炫的;找到图数据可视化分析组件的总结,不过这些有很多是需要收费的
继续找方案,在这里看到说使用微云数据库的中文版本可以实现,我一想有可能是我Neo4j版本不对的缘故,我这个是用的原生英文版的,所以接下来试下用Neo4j中文版行不行得通
装好中文版后启动,却提示说jdk版本过低,只好重新弄java环境了
2.java环境配置
卸载旧版java
$ sudo apt-get autoremove default-jdk
发现没有卸载干净,于是采用下面的方法彻底删除
$ sudo apt-get update
$ sudo apt-cache search java | awk '{print($1)}' | grep -E -e '^(ia32-)?(sun|Oracle)-java' -e '^openjdk-' -e '^icedtea' -e '^(default|gcj)-j(re|dk)' -e '^gcj-(.*)-j(re|dk)' -e 'java-common' | xargs sudo apt-get -y remove
$ sudo apt-get -y autoremove
$ dpkg -l | grep ^rc | awk '{print($2)}' | xargs sudo apt-get -y purge
$ bash -c 'ls -d /home/*/.java' | xargs sudo rm -rf
$ rm -rf /usr/lib/jvm/*
然后通过java -version测试现在是找不到java了
安装jdk-11
通过官网下载实在太慢了,就借助阿里云快速下载 Oracle JDK
下完jdk-11.0.7_linux-x64_bin.tar.gz后,解压
$ tar -zxf jdk-11.0.7_linux-x64_bin.tar.gz jdk-11.0.7/
配置jdk环境变量,打开/etc/profile文件,复制下面配置信息
# set openjdk environment
export JAVA_HOME=~/jdk-11.0.7
export PATH=$JAVA_HOME/bin:$PATH
命令行输入java -version后没有找到java,再按照以下命令安装
$ sudo apt install openjdk-11-jre-headless
现在再输入java -version就有了openjdk版本信息了
3.安装Neo4j中文版
通过这里下载neo4j-chs-community-4.2.4-unix.tar.gz
解压
$ tar -xf neo4j-chs-community-4.2.4-unix.tar.gz
在neo4j-chs-community-4.2.4-unix文件夹下启动
$ ./bin/neo4j console
通过浏览器访问http://localhost:7474/,填写用户名密码进行身份验证
现在就登录到Neo4j中文版本了,版权归微云数聚
这时再尝试将图片加入节点
CREATE(GoogleAssistant:product{name:"GoogleAssistant",image:"https://ftp.bmp.ovh/imgs/2021/04/1de8fc066c18c7cc.png"}),(xiaoice:product{name:"xiaoice",image:"https://ftp.bmp.ovh/imgs/2021/04/2623bcfacf3cbc51.jpg"}),(Siri:product{name:"Siri",image:"https://ftp.bmp.ovh/imgs/2021/04/05d8dc07df1ad3d4.png"}),(Alexa:product{name:"Alexa",image:"https://ftp.bmp.ovh/imgs/2021/04/99ca6d89db9d04f5.png"}),(Microsoft:company{name:"Microsoft",image:"https://ftp.bmp.ovh/imgs/2021/04/b1aeaca54dac2d81.jpg"}),(Google:company{name:"Google",image:"https://ftp.bmp.ovh/imgs/2021/04/a03413875cbf5078.jpg"}),(Apple:company{name:"Apple",image:"https://ftp.bmp.ovh/imgs/2021/04/19dac3fd5c7e19fa.jpg"}),(Amazon:company{name:"Amazon",image:"https://ftp.bmp.ovh/imgs/2021/04/95ab7b479bdd421f.jpg"}),(chatbot:product{name:"chatbot",image:"https://ftp.bmp.ovh/imgs/2021/04/e31fb276287ee33b.jpeg"}),(Google)-[:develop]->(GoogleAssistant),(Microsoft)-[:develop]->(xiaoice),(Apple)-[:develop]->(Siri),(Amazon)-[:develop]->(Alexa),(GoogleAssistant)-[:attribute]->(chatbot),(xiaoice)-[:attribute]->(chatbot),(Siri)-[:attribute]->(chatbot), (Alexa)-[:attribute]->(chatbot)
注意这里的节点名称不要有空格
查看结果
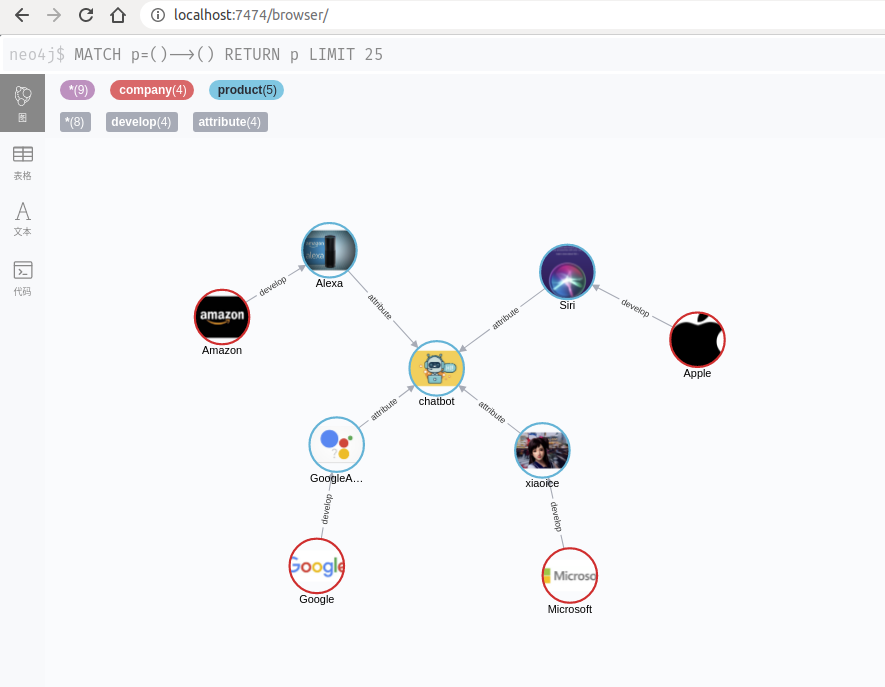
这里简单显示Google,Microsoft,Apple,Amazon四家公司各自开发语音助手情况
测试可行性方面初有成效,止步于此大有入宝山而空手回的意味,现在尝试探索复杂高级的玩法
想到之前有看过三国人物关系知识图谱的项目,里面建模了三国里的人物关系网,只是对于人物的展示只有干巴巴的名字,要是有人物的头像就更赏心悦目了,于是有了改进的方向
首先找到构建知识图谱的json数据,发现里面有”avatar”图片这一属性,溯源去找图片数据集
然后有了本地图片数据,需要想办法批量转换成在线图片网址
1)用sm.ms图床
在sm.ms注册获得账号密码
imageurl.py
import json
import os
import requests
BASE_PATH = 'https://sm.ms/api/v2/'
class SMMS:
def __init__(self, username, password):
self.login_success = False
self.api_key = None
self.username = username
self.password = password
def login(self):
"""
登录SMMS username,password
:return:
"""
result = self.__post('token', data={'username': self.username, 'password': self.password})
#print(result)
self.login_success = "60hRkq3qxIfSULneadNwees9AWipgtPj"
#result['success']
#if self.login_success:
#self.api_key = result['data']['token']
return self.login_success
def upload_image(self, file_path):
"""
图片上传
:param file_path:
:return:
"""
if not (os.path.exists(file_path) and os.path.isfile(file_path)):
Exception("请见检查文件!")
headers = {}
if self.login_success:
headers['Authorization'] = self.api_key
return self.__post(url='upload', headers=headers, files={'smfile': open(file_path, 'rb+')})
def upload_image_2markdown(self, file_path):
result = self.upload_image(file_path)
return result
def upload_history(self):
if format != 'xml' and format == 'json':
Exception('输出格式错误!可选值有 json、xml')
if self.login_success:
Exception('请先登录!')
return self.__get('history', headers={
'Content-Type': 'multipart/form-data',
'Authorization': self.api_key
})
def profile(self):
if format != 'xml' and format == 'json':
Exception('输出格式错误!可选值有 json、xml')
if self.login_success:
Exception('请先登录!')
return self.__get('profile', headers={
'Content-Type': 'multipart/form-data',
'Authorization': self.api_key
})
@staticmethod
def __post(url, data=None, headers=None, files=None):
r = SMMS.__req('POST', url, data=data, headers=headers, files=files)
return r
@staticmethod
def __get(url, params=None, headers=None, files=None):
r = SMMS.__req('GET', url, params=params, headers=headers, files=files)
return r
@staticmethod
def __req(method, url, data=None, params=None, headers=None, files=None):
"""
SMMS基础POST请求函数
:param url: 请求地址
:param data: 请求发送的数据
:param headers: 请求头设置
:return:
"""
post = requests.request(method=method, url=f'{BASE_PATH}{url}', params=params, data=data, headers=headers,
files=files)
result_image = ""
if post.status_code == 200:
result = json.loads(post.content.decode(encoding='utf-8'))
print(result)
if "images" in result:
result_image = result["images"]
print(result_image)
return result_image
if __name__ == '__main__':
smms = SMMS('smou', 'mimaJosm123504')
smms.login()
filepath="本地图片文件夹地址"
dirs = os.listdir(filepath)
url_list = []
for file in dirs:
data_name = file.replace(".jpg","")
image_path = filepath+file
k = smms.upload_image_2markdown(image_path)
print(k)
url_list.append((data_name,k))
print(url_list)
这里会有sm.ms的一些坑,对图片上传会有限制,比如会报错:
{‘success’: False, ‘code’: ‘flood’, ‘message’: ‘Flood detected. You can only upload 20 images per hour’, ‘RequestId’: ‘AF0B171E-2920-483C-A74B-CB30246669B9’}
{‘success’: False, ‘code’: ‘flood’, ‘message’: ‘Flood detected. You can only upload 10 images per minute’, ‘RequestId’: ‘19713E19-1CEE-40B7-8239-F0839239DCB7’}
{‘success’: False, ‘code’: ‘flood’, ‘message’: ‘Flood detected. You can only upload 30 images per day’, ‘RequestId’: ‘2847187F-2EAA-4FA8-AC7A-0D2F2F2164BC’}
简直三连杀有没有
优化代码加了
import time
time.sleep(180)
对图片进行批量处理,整体-已完成=未完成
import os
import sys
import shutil
source_dir = r'源地址'
target_dir = r'目标地址'
file_list = [文件名列表]
for file_name in file_list:
shutil.copy( source_dir+file_name , target_dir )
得到(本地图片,在线图片地址)元组列表exist_list
2)用七牛云图床
鉴于sm.ms的坑深,尝试用七牛云来获得图片链接
然而新建存储空间时要进行个人用户实名认证,这也是个坑,没有必要再进行下去了
3)用github建图床
在github上新建一个仓库用来存储图片,这时就可以得到图片链接了,格式为 https://github.com/用户名/仓库名/图片名
通过github图片链接下载很慢的话可以用https://hub.fastgit.org/ 来加速,如
https://hub.fastgit.org/用户名/仓库名/blob/master/threekingdoms_images/avatars/刘宏.jpg
现在用py2neo操作neo4j图数据库
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import py2neo
import pymongo
import os
import json
import requests
import re
import time
exist_list = [('张承2.jpg', 'https://i.loli.net/2021/04/01/ipYDyUzHoSdX5r4.jpg'), ('张宝.jpg', 'https://i.loli.net/2021/04/01/tygBCS8ed2afMhW.jpg'), ('孙权.jpg', 'https://i.loli.net/2021/04/01/9Qrj4CvDgkRZIqL.jpg'), ('张既.jpg', 'https://i.loli.net/2021/04/01/X4gD79kJyGuK1WO.jpg'), ('张杨.jpg', 'https://i.loli.net/2021/04/01/R4nMgGpv1Z3JQr8.jpg'), ('刘备.jpg', 'https://i.loli.net/2021/04/01/4lUCjKT9G5mXaeb.jpg'), ('张苞.jpg', 'https://i.loli.net/2021/04/01/GJWvIeotSazcDMk.jpg'), ('张松.jpg', 'https://i.loli.net/2021/04/01/6n3JbQEhl7Yq1Uu.jpg'), ('张绣.jpg', 'https://i.loli.net/2021/04/01/ROdA3tqwCag8ri2.png'), ('张象.jpg', 'https://i.loli.net/2021/04/01/WkUhqdBKbON9Dof.jpg'), ('张衡.jpg', 'https://i.loli.net/2021/04/01/2O5U3DuJTpFPg48.jpg'), ('张卫.jpg', 'https://i.loli.net/2021/04/01/2CHFRKXawmGbgVh.jpg'), ('张嶷.jpg', 'https://i.loli.net/2021/04/01/AtrmyBqIEk2cYhJ.jpg'), ('张钧.jpg', 'https://i.loli.net/2021/04/01/iau4cJpNRkELFe5.jpg'), ('张南2.jpg', 'https://i.loli.net/2021/04/01/Stw7vpQBZidWEfY.jpg'), ('张温2.jpg', 'https://i.loli.net/2021/04/01/Vg5HXxlDuPM7A18.jpg'), ('张俭.jpg', 'https://i.loli.net/2021/04/01/j9UIePqlTyF2SHV.jpg'), ('张飞.jpg', 'https://i.loli.net/2021/04/01/rE2QXnpjLSubNhC.jpg'), ('张特.jpg', 'https://i.loli.net/2021/04/01/wsB1mTVdnlNAu4P.jpg'), ('张翼.jpg', 'https://i.loli.net/2021/04/01/LrwHbcETNlxOUVD.jpg'), ('张温1.jpg', 'https://i.loli.net/2021/03/30/Em8HgGefBVC1WzS.jpg'), ('张绍.jpg', 'https://i.loli.net/2021/03/30/zPE19Zvu3rk7elj.jpg'), ('张郃.jpg', 'https://i.loli.net/2021/03/30/6glwvQK2Dt1MLOW.jpg'), ('张勋.jpg', 'https://i.loli.net/2021/03/30/Ii6AwMqmHXuZzyP.jpg'), ('张鲁.jpg', 'https://i.loli.net/2021/03/30/yQTE3AidbGVesrL.jpg'), ('张著.jpg', 'https://i.loli.net/2021/03/30/UmRWylGf6vtOMhT.jpg'), ('张休.jpg', 'https://i.loli.net/2021/03/30/IFuUcZ8D3zxYjhC.jpg'), ('诸葛亮.jpg', 'https://i.loli.net/2021/03/30/CsbPVhwXvgAQtM4.jpg'), ('曹操.jpg', 'https://i.loli.net/2021/03/30/xELuAqaXG9fOjk1.jpg'), ('张燕.jpg', 'https://i.loli.net/2021/03/30/nEwYXyRW7IeDcoi.jpg'), ('张英.jpg', 'https://i.loli.net/2021/03/30/AotFk9TZUel4MQi.jpg'), ('张肃.jpg', 'https://i.loli.net/2021/03/30/cANlKsSTPUHrqyE.jpg'), ('张横.jpg', 'https://i.loli.net/2021/03/30/QJk4bi59T2dK7hU.jpg'), ('张世平.jpg', 'https://i.loli.net/2021/04/01/5NFvksYxcEurKlA.jpg'), ('刘琦.jpg', 'https://i.loli.net/2021/04/01/BxmgiYNLp7rXwA2.jpg'), ('刘宠.jpg', 'https://i.loli.net/2021/04/01/NzGWb5xJvyUDl8S.jpg'), ('刘舆.jpg', 'https://i.loli.net/2021/04/01/6lBdxKQqJ2hOcYV.jpg'), ('刘虞.jpg', 'https://i.loli.net/2021/04/01/WeiYT7LGncbJgZ5.jpg'), ('刘焉.jpg', 'https://i.loli.net/2021/04/01/Vlfy9R3LpPsiehr.jpg'), ('刘宏.jpg', 'https://i.loli.net/2021/04/01/KIDXJV9QTNf2b7R.jpg'), ('张南1.jpg', 'https://i.loli.net/2021/04/01/6r1juyt7EUzs5pv.jpg'), ('张允.jpg', 'https://i.loli.net/2021/04/01/XO2SyNBzhE5GUsx.jpg'), ('张华.jpg', 'https://i.loli.net/2021/04/01/2wkzelhSisUWRby.jpg'), ('刘繇.jpg', 'https://i.loli.net/2021/04/01/JOH7wQMqjbKX1rU.jpg'), ('张举.jpg', 'https://i.loli.net/2021/04/01/X1IAclDB6qmyr5i.jpg'), ('刘表.jpg', 'https://i.loli.net/2021/04/01/ULfns5ZNW4Dbjyo.jpg'), ('张武.jpg', 'https://i.loli.net/2021/04/01/lf9CptdzuaMiZsI.jpg'), ('张济.jpg', 'https://i.loli.net/2021/04/01/2cinQzuMTeha3fX.jpg'), ('张任.jpg', 'https://i.loli.net/2021/04/01/a8As7xYOBClTnUp.jpg'), ('张梁.jpg', 'https://i.loli.net/2021/04/01/8TmbCSB2pY4GyQD.jpg'), ('张悌.jpg', 'https://i.loli.net/2021/04/01/SQvmgVe5E1N72at.jpg'), ('张昭.jpg', 'https://i.loli.net/2021/04/01/ZeGog2EBtvipVnC.jpg'), ('张虎.jpg', 'https://i.loli.net/2021/04/01/pLQKMuo2creN7Ed.jpg'), ('张布.jpg', 'https://i.loli.net/2021/04/01/oBktFQicK7EjV9D.png'), ('张纯.jpg', 'https://i.loli.net/2021/04/01/ZoyGFhblgE1dSVv.jpg'), ('张缉.jpg', 'https://i.loli.net/2021/04/01/PAwExJCheBrtVUy.jpg'), ('张纮.jpg', 'https://i.loli.net/2021/04/01/VhIEkKJpdbOCawX.jpg'), ('张裔.jpg', 'https://i.loli.net/2021/04/01/qEPUe45ZLrXpKNd.png'), ('张辽.jpg', 'https://i.loli.net/2021/04/01/zglTDhApEkarJYd.jpg'), ('张超.jpg', 'https://i.loli.net/2021/04/01/ROFKLu2Ahc1nedv.jpg'), ('张达.jpg', 'https://i.loli.net/2021/04/01/gndmipqZ7xk8tXE.jpg'), ('张角.jpg', 'https://i.loli.net/2021/04/01/H3talEcPAFbZDhW.jpg'), ('张道陵.jpg', 'https://i.loli.net/2021/04/01/Ib36y5BrNOmojTV.jpg'), ('张让.jpg', 'https://i.loli.net/2021/04/01/a6zrMSh1etVu2Po.jpg'), ('张闿.jpg', 'https://i.loli.net/2021/04/01/QL4PGMZ2Vj5svUO.jpg'), ('张邈.jpg', 'https://i.loli.net/2021/04/01/j51OyiZsqc7HnRw.png'), ('张遵.jpg', 'https://i.loli.net/2021/04/01/ECNkqaRc7ljSrGe.jpg')]
file_exist = [x[0] for x in exist_list]
def get_data(filepath="./characters/"):
dirs = os.listdir(filepath)
outpout =[]
path_list = []
for file in dirs:
datarow = open(filepath+file,"r",encoding="utf-8").readlines()
for j in range(len(datarow)):
if "avatar" in datarow[j]:
try:
print(j)
print(datarow[j])
print(type(datarow[j]))
data_delete = re.findall(r": (.+?),",datarow[j])[0]
print(data_delete)
data_name = re.findall(r"avatars/(.+?).jpg",data_delete)[0]
print(data_name)
if data_name+".jpg" in file_exist:
fileindex = file_exist.index(data_name+".jpg")
datarow[j] = datarow[j].replace(data_delete,"\""+exist_list[fileindex][1]+"\"")
print(datarow[j])
outpout.append(datarow)
except:
pass
print(path_list)
return outpout
def create_node(label,node_ls,kg):
for n,i in node_ls:
node = py2neo.Node(label,name=n,image=i)
try:
kg.create(node)
except:
print("建立%s节点时报错"%label)
def two_str(input):
if type(input) ==str:
return input
if type(input) ==list:
return ",".join(i for i in input)
def two_ls(input):
if type(input) == list:
return input
if type(input) == str:
if "," in input:
return input.split(",")
else:
return [input]
def extract_data_and_create_node(data):
kg = py2neo.Graph(
"http://localhost:7474",
username="neo4j",
password="neo4j",
)
name_ls = []
monarch_ls = []
for row in data:
row = json.loads("".join(i for i in row))
name_ls.append((row["name"],row["avatar"]))
monarch_ls.append(row["monarch"])
name_ls = list(set(name_ls))
print(name_ls)
create_node("people",name_ls,kg)
create_monarch_rel(data,kg)
create_faction_rel(data,kg)
def create_monarch_rel(data,kg):
for row in data:
row = json.loads("".join(i for i in row))
name = row["name"]
if row.get("monarch"):
monarch = row["monarch"]
monarch = two_ls(two_str(monarch))
for i in monarch:
order = "match(n:people) where n.name = '%s' " \
"match(m:people) where m.name= '%s'" \
"merge (n)-[r:has_monarch]-(m)"%(name,i)
kg.run(order)
def create_faction_rel(data,kg):
for row in data:
row = json.loads("".join(i for i in row))
name = row["name"]
if row.get("faction"):
faction = row["faction"]
faction = two_ls(two_str(faction))
for i in faction:
order = "match(n:people) where n.name = '%s' " \
"match(m:faction) where m.name= '%s'" \
"merge (n)-[r:work_for_faction]-(m)"%(name,i)
kg.run(order)
if __name__ == '__main__':
data = get_data()
extract_data_and_create_node(data)
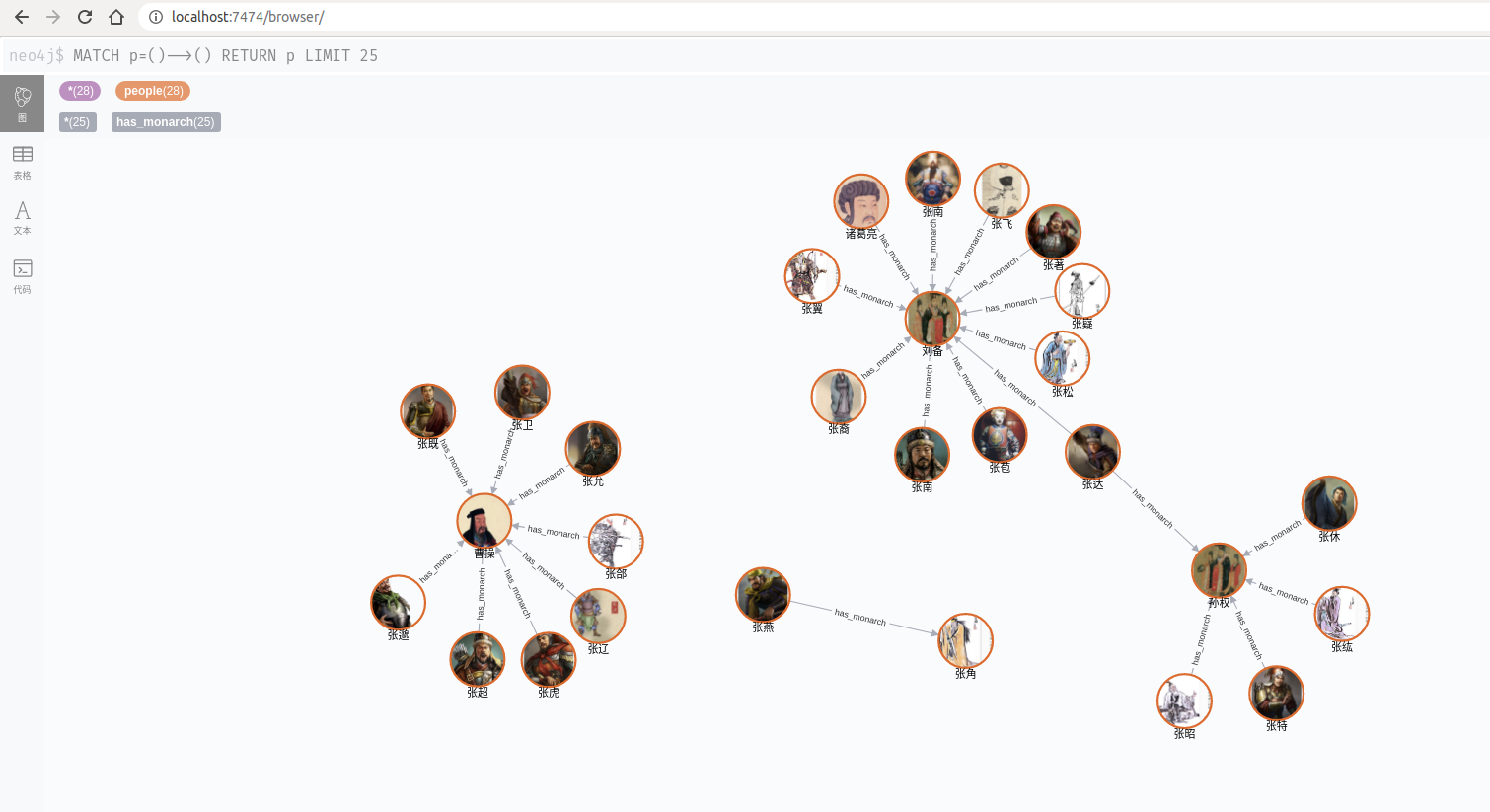
到此大功告成了!
在解决问题的过程中也发现了一些宝藏,比如d3.js可视化neo4j图数据库项目, 综述阅读–多模态数据库,收藏留待之后有时间研读学习