基于Trankit的多语种命名实体识别
1.前言
本文是Multilingual NLP学习笔记系列专栏的第一篇文章,希望等专栏完结自己回头再看这篇文章时,心里可以默默打个弹幕:“梦开始的地方”。其实很早之前就想写与多语种NLP相关内容,但作为拖延症晚期患者,总会给自己找借口说还没准备好担心会写得糟糕。经过一番波折终于意识到完成比完美更重要,未来更强的自己不是等来的,而是实践迭代出来的。以此整理学习笔记作为开篇,用输出倒逼输入,迈出第一步,让美好的起源成为自证预言。欢迎大家批评指正,分享交流,非常感谢!
2. Trankit简介
-
Trankit名字
起名字是个艺术活,既要能表明自己是怎么来的(from),又需指明自己要去哪儿能做什么(to),在这两方面Trankit都做到了。一开始看到Trankit,我就在猜这货是不是跟transformer有关系啊,看着都姓tran。果不其然,看到论文标题Trankit: A Light-Weight Transformer-based Toolkit for Multilingual Natural Language Processing,恍然大悟,原来就是基于Transformer做的轻量级多语种工具箱。想想我们的名字大多数不也是继承了父母的姓氏、承载了父母的希冀?如果能做到人如其名,名副其实,那也是难能可贵的事情。
-
Trankit优缺点
- 优点:轻量级,内存占用小,预训练pipeline支持56种语言,其中包括文言文,性能超越Stanza
- 缺点:在中文处理方面不如专业的中文NLP工具,在工业落地功能上没有spaCy功能丰富
-
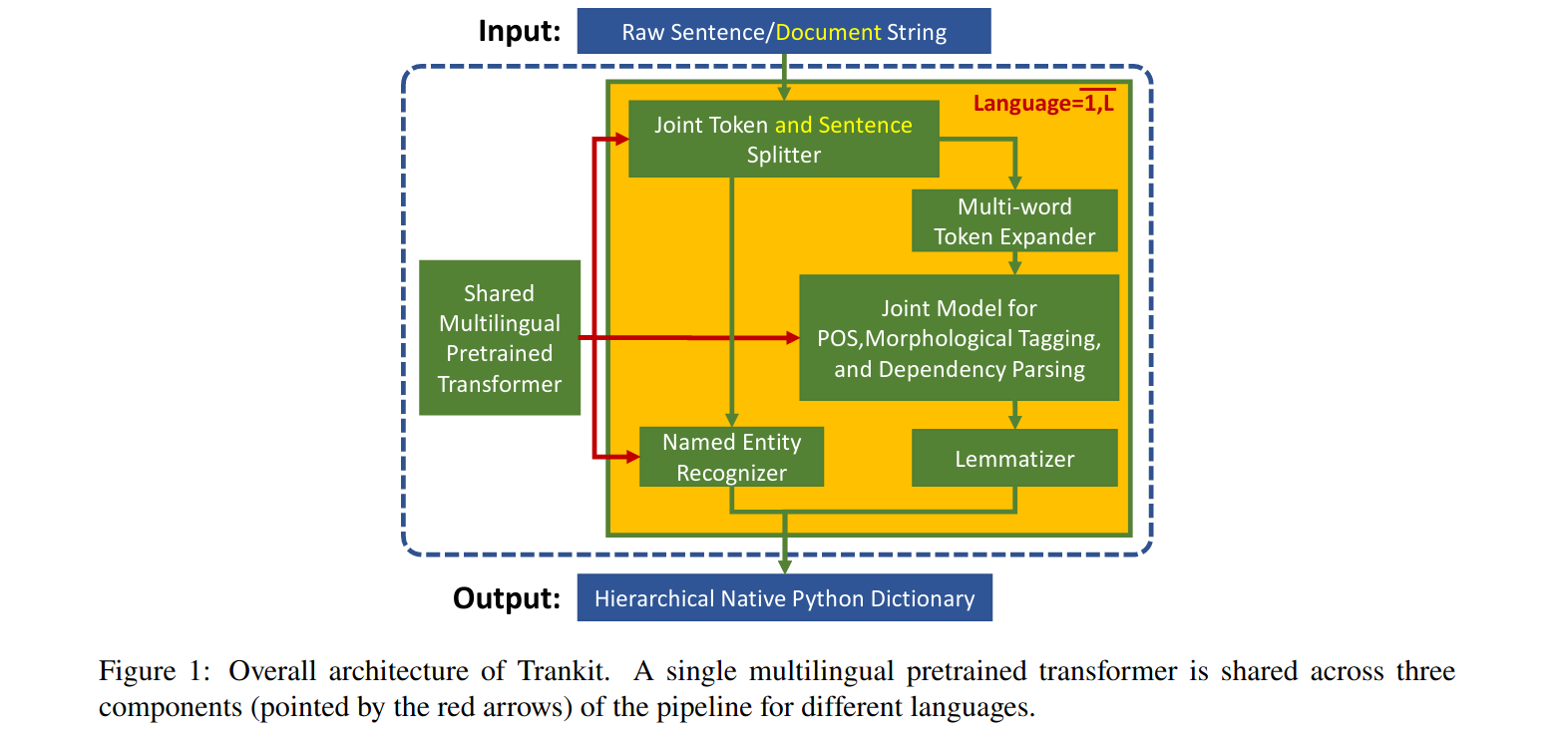
Trankit原理
首先利用基于共享多语种预训练transformer的XLM-Roberta模型构建三个模块: the joint token and sentence splitter; the joint model for part-of-speech, morphological tagging, and dependency parsing; the named entity recognizer,最新版本用的是XLM-Roberta Large.
然后为每种语言创建基于即插即用 (plug-and-play)机制的适配器(Adapters)。在训练时,共享的大预训练transformer权重固定,只有适配器和任务特定权重被更新;在推理时,根据输入文本的语言和当前的活动组件,相应经过训练的适配器和特定任务权重被激活并加入到pipeline去处理输入数据。
3. Trankit安装
安装
$ sudo pip3 install trankit -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
auto模式能够自动识别语种并处理相应任务
from trankit import Pipeline
p = Pipeline('auto')
一旦开启 auto 模式,p = Pipeline('auto'),就是把各个语言的模型都要下载加载出来,我是下了好久中断了几次才完整下完模型,不容易啊
看看这加载的模型以及支持的语言有哪些:
Loading pretrained XLM-Roberta, this may take a while...
Loading tokenizer for afrikaans
Loading tagger for afrikaans
Loading lemmatizer for afrikaans
Loading tokenizer for arabic
Loading tagger for arabic
Loading multi-word expander for arabic
Loading lemmatizer for arabic
Loading NER tagger for arabic
Loading tokenizer for armenian
Loading tagger for armenian
Loading multi-word expander for armenian
Loading lemmatizer for armenian
Loading tokenizer for basque
Loading tagger for basque
Loading lemmatizer for basque
Loading tokenizer for belarusian
Loading tagger for belarusian
Loading lemmatizer for belarusian
Loading tokenizer for bulgarian
Loading tagger for bulgarian
Loading lemmatizer for bulgarian
Loading tokenizer for catalan
Loading tagger for catalan
Loading multi-word expander for catalan
Loading lemmatizer for catalan
Loading tokenizer for chinese
Loading tagger for chinese
Loading lemmatizer for chinese
Loading NER tagger for chinese
Loading tokenizer for croatian
Loading tagger for croatian
Loading lemmatizer for croatian
Loading tokenizer for czech
Loading tagger for czech
Loading multi-word expander for czech
Loading lemmatizer for czech
Loading tokenizer for danish
Loading tagger for danish
Loading lemmatizer for danish
Loading tokenizer for dutch
Loading tagger for dutch
Loading lemmatizer for dutch
Loading NER tagger for dutch
Loading tokenizer for english
Loading tagger for english
Loading lemmatizer for english
Loading NER tagger for english
Loading tokenizer for estonian
Loading tagger for estonian
Loading lemmatizer for estonian
Loading tokenizer for finnish
Loading tagger for finnish
Loading multi-word expander for finnish
Loading lemmatizer for finnish
Loading tokenizer for french
Loading tagger for french
Loading multi-word expander for french
Loading lemmatizer for french
Loading NER tagger for french
Loading tokenizer for galician
Loading tagger for galician
Loading multi-word expander for galician
Loading lemmatizer for galician
Loading tokenizer for german
Loading tagger for german
Loading multi-word expander for german
Loading lemmatizer for german
Loading NER tagger for german
Loading tokenizer for greek
Loading tagger for greek
Loading multi-word expander for greek
Loading lemmatizer for greek
Loading tokenizer for hebrew
Loading tagger for hebrew
Loading multi-word expander for hebrew
Loading lemmatizer for hebrew
Loading tokenizer for hindi
Loading tagger for hindi
Loading lemmatizer for hindi
Loading tokenizer for hungarian
Loading tagger for hungarian
Loading lemmatizer for hungarian
Loading tokenizer for indonesian
Loading tagger for indonesian
Loading lemmatizer for indonesian
Loading tokenizer for irish
Loading tagger for irish
Loading lemmatizer for irish
Loading tokenizer for italian
Loading tagger for italian
Loading multi-word expander for italian
Loading lemmatizer for italian
Loading tokenizer for japanese
Loading tagger for japanese
Loading lemmatizer for japanese
Loading tokenizer for kazakh
Loading tagger for kazakh
Loading multi-word expander for kazakh
Loading lemmatizer for kazakh
Loading tokenizer for korean
Loading tagger for korean
Loading lemmatizer for korean
Loading tokenizer for kurmanji
Loading tagger for kurmanji
Loading lemmatizer for kurmanji
Loading tokenizer for latin
Loading tagger for latin
Loading lemmatizer for latin
Loading tokenizer for latvian
Loading tagger for latvian
Loading lemmatizer for latvian
Loading tokenizer for lithuanian
Loading tagger for lithuanian
Loading lemmatizer for lithuanian
Loading tokenizer for marathi
Loading tagger for marathi
Loading multi-word expander for marathi
Loading lemmatizer for marathi
Loading tokenizer for norwegian-nynorsk
Loading tagger for norwegian-nynorsk
Loading lemmatizer for norwegian-nynorsk
Loading tokenizer for norwegian-bokmaal
Loading tagger for norwegian-bokmaal
Loading lemmatizer for norwegian-bokmaal
Loading tokenizer for persian
Loading tagger for persian
Loading multi-word expander for persian
Loading lemmatizer for persian
Loading tokenizer for polish
Loading tagger for polish
Loading multi-word expander for polish
Loading lemmatizer for polish
Loading tokenizer for portuguese
Loading tagger for portuguese
Loading multi-word expander for portuguese
Loading lemmatizer for portuguese
Loading tokenizer for romanian
Loading tagger for romanian
Loading lemmatizer for romanian
Loading tokenizer for russian
Loading tagger for russian
Loading lemmatizer for russian
Loading NER tagger for russian
Loading tokenizer for serbian
Loading tagger for serbian
Loading lemmatizer for serbian
Loading tokenizer for slovak
Loading tagger for slovak
Loading lemmatizer for slovak
Loading tokenizer for slovenian
Loading tagger for slovenian
Loading lemmatizer for slovenian
Loading tokenizer for spanish
Loading tagger for spanish
Loading multi-word expander for spanish
Loading lemmatizer for spanish
Loading NER tagger for spanish
Loading tokenizer for swedish
Loading tagger for swedish
Loading lemmatizer for swedish
Loading tokenizer for tamil
Loading tagger for tamil
Loading multi-word expander for tamil
Loading lemmatizer for tamil
Loading tokenizer for telugu
Loading tagger for telugu
Loading lemmatizer for telugu
Loading tokenizer for turkish
Loading tagger for turkish
Loading multi-word expander for turkish
Loading lemmatizer for turkish
Loading tokenizer for ukrainian
Loading tagger for ukrainian
Loading multi-word expander for ukrainian
Loading lemmatizer for ukrainian
Loading tokenizer for urdu
Loading tagger for urdu
Loading lemmatizer for urdu
Loading tokenizer for uyghur
Loading tagger for uyghur
Loading lemmatizer for uyghur
Loading tokenizer for vietnamese
Loading tagger for vietnamese
Loading lemmatizer for vietnamese
Loading NER tagger for vietnamese
==================================================
Trankit is in auto mode!
Available languages: ['afrikaans', 'arabic', 'armenian', 'basque', 'belarusian', 'bulgarian', 'catalan', 'chinese', 'croatian', 'czech', 'danish', 'dutch', 'english', 'estonian', 'finnish', 'french', 'galician', 'german', 'greek', 'hebrew', 'hindi', 'hungarian', 'indonesian', 'irish', 'italian', 'japanese', 'kazakh', 'korean', 'kurmanji', 'latin', 'latvian', 'lithuanian', 'marathi', 'norwegian-nynorsk', 'norwegian-bokmaal', 'persian', 'polish', 'portuguese', 'romanian', 'russian', 'serbian', 'slovak', 'slovenian', 'spanish', 'swedish', 'tamil', 'telugu', 'turkish', 'ukrainian', 'urdu', 'uyghur', 'vietnamese']
4. Trankit应用-双语新闻的命名实体识别
想着用 trankit 做什么以便测试一下其轻便且强大的功能,这个有点像拿着锤子找钉子,当然这个是为了找到应用场景以实践做到学以致用。做点什么好呢?有了,有个痛点急需解决:平日工作繁忙,但又想了解下世界新闻以广见识,只能抽出一小会时间浏览一下多语种新闻网站。如果从文章可以抽取出有意义的实体,那大致上可以了解到这文章讲的与什么相关,如此一来就可以在节省时间成本的情况下缓解信息焦虑综合症。
比较遗憾的是trankit没有文本摘要的功能模块,不过我思考了一下,其实有NER就足够了,理由如下
1) 可替代性:
可以从识别出的实体定位到相应句子,补充上下文信息,大致可以代替文本摘要,简单粗暴有效
2) 必要性:
现在打脸反转的新闻实在是太多了,铺天盖地,现在大家抱着吃瓜的心态去看待社会现象,立马站队表立场很容易翻车的,谈论对错并不重要,谈论什么对象才重要,这个时候就体现出实体的优越性了,我只需要知道这条热点资讯是关于什么的,对于时事抓大放小,把稀缺的注意力留给真正需要的事情上。
3) 有效性:
《知识大迁移》这本书里有这样一句话令人印象深刻
“有一样东西你没法上谷歌搜索,那就是你不知道自己应该搜索什么。”
在搜索引擎中用关键词比用整句更能得到比较好的搜索结果,实体词可以高效帮助扩充我们的可搜索信息空间,以点带面。
理清了需求,现在开始实践去解决问题
-
准备测试语料
数据来源有中英双语新闻 bilingual.txt
为什么一拿起书就犯困? - Chinadaily.com.cn
原神早玉角色法语介绍 GenshinImpact.txt
Genshin Impact : Guide du personnage Sayu — Armes, artefacts et talents
-
trankit_ner_test.py
from trankit import Pipeline
import pandas as pd
from pandas.core.frame import DataFrame
#frame输出完整
pd.options.display.max_rows = None
p = Pipeline('english',gpu=True)
p.add('chinese')
p.add('french')
p.set_auto(True)
def trankit_ner(file_path):
txt_file = open(file_path, 'r')
ner_unite = []
ner_single = []
ner_type = []
ner_lang = []
for line in txt_file.readlines():
line = line.strip("\n").replace("\n", "")
#去除多余的空行,保证字符串有意义
if line in ['\n','\r\n'] or line.strip() == "":
pass
else:
#print(line)
ner_output = p.ner(line)
sent = ner_output['sentences']
#sent_lang表示语种识别的语言名称
sent_lang = ner_output['lang']
for sent_part in sent:
tokens_info = sent_part['tokens']
for token in tokens_info:
#"O"表示不属于任何实体类型,是无意义的,需要过滤掉
if token['ner'] != "O":
#合并NER的开始、中间、结束
if 'B-' in token['ner']:
ner_unite.append(token['text'])
continue
elif 'I-' in token['ner']:
#print(token['ner'])
ner_unite.append(token['text'])
continue
elif 'E-' in token['ner']:
ner_unite.append(token['text'])
#print(ner_unite)
if sent_lang == "chinese":
ner_single.append(''.join(ner_unite))
else:
#当遇到非中文语言时用_将分割的NER部分相连,不然会影响阅读,印欧语系中的语言以表音构成,用空格来区分单词
ner_single.append('_'.join(ner_unite))
ner_type.append(token['ner'].replace("E-", ""))
ner_lang.append(sent_lang)
ner_unite = []
else:
#其他情况表示NER部分没有被分割掉,可单独成实体
ner_single.append(token['text'])
ner_type.append(token['ner'])
ner_lang.append(sent_lang)
#print(ner_single)
ner_dict = {"entity":ner_single,"type":ner_type,"lang":ner_lang}
ner_frame = DataFrame(ner_dict)
return ner_frame
if __name__ == '__main__':
ner_result = trankit_ner('bilingual.txt')
#ner_result = trankit_ner('GenshinImpact.txt')
print(ner_result)
- 测试结果
中英双语新闻 bilingual.txt
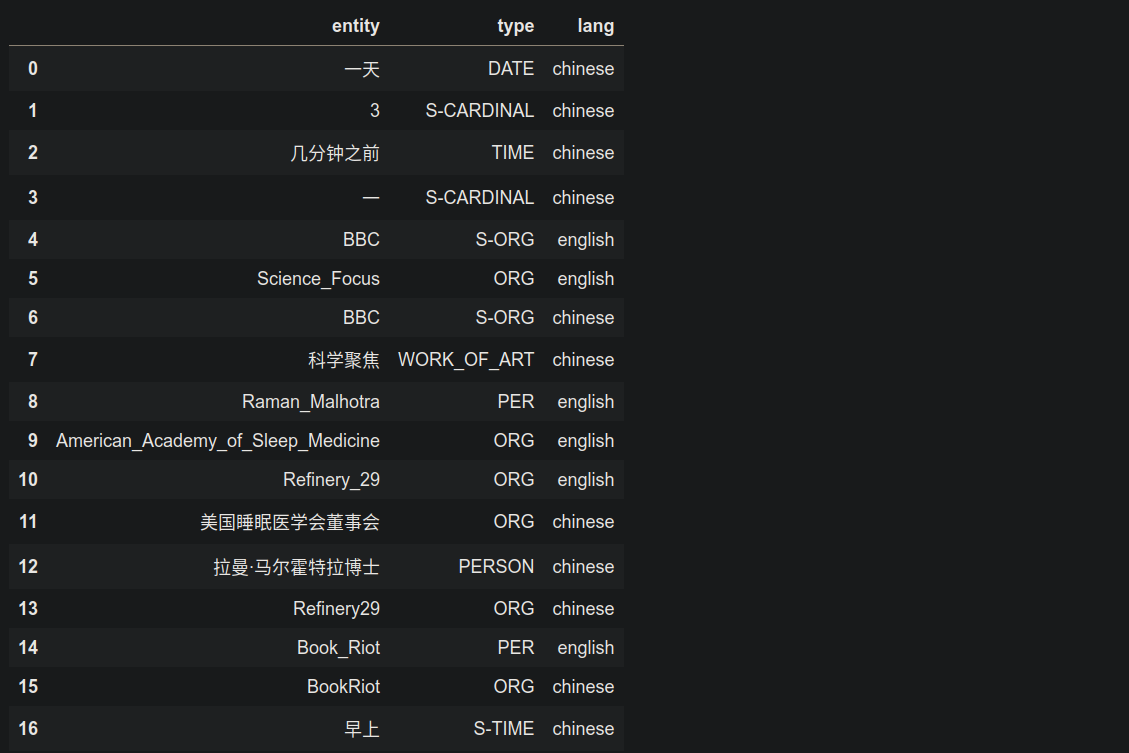
原神早玉角色法语介绍 GenshinImpact.txt
输出结果
| entity | type | lang | |
|---|---|---|---|
| 0 | Genshin_Impact_:_Guide_du_personnage_Sayu_—_Ar... | MISC | french |
| 1 | Genshin_Impact | MISC | french |
| 2 | Tanuki | S-PER | french |
| 3 | Genshin_Impact_Sayu | MISC | french |
| 4 | Sayu | S-MISC | french |
| 5 | Yoimiya | S-MISC | french |
| 6 | Tapisserie_des_flammes_d’_or | MISC | french |
| 7 | Sayu | S-PER | french |
| 8 | Sayu | S-PER | french |
| 9 | Genshin_Impact | MISC | french |
| 10 | Katsuragikiri_Nagamasa | MISC | french |
| 11 | Katsuragikiri_Nagamasa | MISC | french |
| 12 | Porte_de_l’_Arsenal | LOC | french |
| 13 | Contes_de_Tatara | MISC | french |
| 14 | Katsuragikiri_Nagamasa | MISC | french |
| 15 | Sayu | S-PER | french |
| 16 | Genshin_Impact | MISC | french |
| 17 | Conduite_de_samouraï | MISC | french |
| 18 | Epée_grise | LOC | french |
| 19 | Epée_grise_sacrificielle | LOC | french |
| 20 | Sayu | S-PER | french |
| 21 | Rainslasher | S-MISC | french |
| 22 | Sayu | S-PER | french |
| 23 | Rainslasher | S-MISC | french |
| 24 | Hydro | S-ORG | french |
| 25 | Electro | S-ORG | french |
| 26 | Pierre_tombale_du_loup | MISC | french |
| 27 | Fierté_du_ciel | MISC | french |
| 28 | Sayu | S-MISC | french |
| 29 | DPS | S-MISC | french |
| 30 | Diluc | S-PER | french |
| 31 | Eula | S-PER | french |
| 32 | Razor | S-PER | french |
| 33 | Sayu | S-PER | french |
| 34 | Gravestone | S-MISC | french |
| 35 | Épine_de_serpent | MISC | french |
| 36 | Sayu_–_Vénérable_Viridescent | MISC | french |
| 37 | Sayu | S-LOC | french |
| 38 | 4_Pieces | MISC | french |
| 39 | Vénérable_Viridescent | PER | french |
| 40 | Anemo | S-LOC | french |
| 41 | Viridescent_Venerer | LOC | french |
| 42 | Valley_of_Remembrance | LOC | french |
| 43 | Sayu | S-PER | french |
| 44 | Anemo | S-PER | french |
| 45 | Swirl | S-LOC | french |
| 46 | Viridescent_Venerer | MISC | french |
| 47 | Wanderer’s_Troupe | MISC | french |
| 48 | Noblesse_Oblige | MISC | french |
| 49 | Gladiator’s_Finale | MISC | french |
| 50 | Shimenawa’s_Reminisce | MISC | french |
| 51 | Viridescent_Venerer | ORG | french |
| 52 | Troupe | S-LOC | french |
| 53 | Noblesse_Oblige | LOC | french |
| 54 | Gladiator_’s | LOC | english |
| 55 | Shimenawa_’s | LOC | english |
| 56 | Viridescent_Venerer | ORG | french |
| 57 | Maiden_Beloved | MISC | french |
| 58 | Sayu | S-MISC | french |
| 59 | ATK | S-MISC | french |
| 60 | Jean | S-LOC | french |
| 61 | Sayu | S-LOC | french |
| 62 | C1 | S-LOC | french |
| 63 | C5 | S-LOC | french |
| 64 | C6 | S-LOC | french |
| 65 | ATK | S-MISC | french |
| 66 | ATK | S-MISC | french |
| 67 | EM | S-MISC | french |
| 68 | C6 | S-LOC | french |
| 69 | Statistiques_des_artefacts_Les_tourbillons | MISC | french |
| 70 | Muji-Muji_Daruma | PER | french |
| 71 | Genshin_Impact_Sayu | MISC | french |
| 72 | Sayu | S-PER | french |
| 73 | Sayu | S-PER | french |
| 74 | Shuumatsuban_Ninja_Blade | MISC | french |
| 75 | Sayu | S-PER | french |
| 76 | Yoohoo_Art | MISC | french |
| 77 | Fuuin_Dash | MISC | french |
| 78 | Sayu | S-PER | french |
| 79 | Sayu | S-LOC | french |
| 80 | Roue_du_vent_de_Fuufuu | LOC | french |
| 81 | Coup | S-LOC | french |
| 82 | Fuufuu | S-LOC | french |
| 83 | FuuFuu_Whirlwind_Kick | MISC | french |
| 84 | Absorption_élémentaire | MISC | french |
| 85 | Pyro | S-LOC | french |
| 86 | Hydro | S-LOC | french |
| 87 | Cryo | S-LOC | french |
| 88 | Electro | S-LOC | french |
| 89 | Sayu | S-PER | french |
| 90 | Art_Yoohoo | MISC | french |
| 91 | Mujina_Fury | MISC | french |
| 92 | Sayu | S-LOC | french |
| 93 | Sayu | S-PER | french |
| 94 | Anemo | S-PER | french |
| 95 | ATK | S-LOC | french |
| 96 | Sayu | S-LOC | french |
| 97 | Muji-Muji_Daruma | ORG | french |
| 98 | HP | S-ORG | french |
| 99 | HP | S-ORG | french |
| 100 | Muji-Muji_Daruma | MISC | french |
| 101 | ATK | S-MISC | french |
| 102 | Sayu | S-LOC | french |
| 103 | Sayu | S-PER | french |
| 104 | Lumière | S-PER | french |
| 105 | Cour_Violette | LOC | french |
| 106 | Nectar_des_mobs_Whopperflower | MISC | french |
| 107 | Balance_dorée_d’_Azhdaha | LOC | french |
| 108 | Talents | S-LOC | french |
| 109 | Art_Yoohoo_:_Silencer’s_Secret | MISC | french |
| 110 | Sayu | S-PER | french |
| 111 | Si | S-MISC | french |
| 112 | Sayu | S-PER | french |
| 113 | Tourbillon | S-MISC | french |
| 114 | Muji-Muji_Daruma | MISC | french |
| 115 | AoE | S-MISC | french |
| 116 | Genshin_Impact | MISC | french |
| 117 | Constellations | S-LOC | french |
| 118 | Constellation_1 | LOC | french |
| 119 | C1 | S-LOC | french |
| 120 | Constellation | S-LOC | french |
| 121 | C1_:_Multi-Task_no_Jutsu_–_Le_Muji-Muji_Daruma | MISC | french |
| 122 | HP | S-ORG | french |
| 123 | FuuFuu | S-LOC | french |
| 124 | Sayu | S-LOC | french |
| 125 | C3 | S-MISC | french |
| 126 | Bunshin | S-MISC | french |
| 127 | Coup_de_pied_le_niveau | MISC | french |
| 128 | Skiving_New_and_Improved | MISC | french |
| 129 | Sayu | S-PER | french |
| 130 | Swirl | S-PER | french |
| 131 | C5 | S-MISC | french |
| 132 | Speed_Comes_First | MISC | french |
| 133 | C6 | S-MISC | french |
| 134 | Sleep_O’Clock_–_Le_Daruma_Muji-Muji | MISC | french |
| 135 | Sayu | S-PER | french |
| 136 | ATK | S-MISC | french |
| 137 | ATK | S-MISC | french |
| 138 | Genshin_Impact_Sayu | MISC | french |
| 139 | Sayu | S-PER | french |
| 140 | Teyvat | S-LOC | french |
| 141 | Whopperflower | S-MISC | french |
| 142 | Vayuda_Turquoise | LOC | french |
| 143 | Anemo_Hypostasis | LOC | french |
| 144 | Maguu_Kenki | LOC | french |
| 145 | Noyau_de_marionnette_–_Lâché_par_le_Maguu_Kenki | MISC | french |
| 146 | île_Yashiori | LOC | french |
| 147 | Kannazuka | S-LOC | french |
| 148 | Sayu | S-PER | french |
| 149 | Sayu | S-PER | french |
| 150 | Genshin_Impact | MISC | french |
| 151 | Anemo | S-PER | french |
| 152 | Venti | S-PER | french |
| 153 | Venti | S-PER | french |
| 154 | Kazuha | S-MISC | french |
| 155 | Ce | S-LOC | french |
| 156 | Xiao | S-PER | french |
| 157 | Sucrose | S-PER | french |
| 158 | C6 | S-MISC | french |
| 159 | Jean | S-MISC | french |
| 160 | sub-DPS | S-MISC | french |
| 161 | Jean | S-MISC | french |
| 162 | Sayu | S-MISC | french |
| 163 | Coup_de_pied_tourbillonnant_de_Fuufuu | LOC | french |
| 164 | Sayu | S-PER | french |
| 165 | Kazuha | S-LOC | french |
| 166 | Venti | S-LOC | french |
| 167 | Sucrose | S-PER | french |
| 168 | C6 | S-MISC | french |
| 169 | Kazuha | S-PER | french |
| 170 | Sucrose | S-PER | french |
| 171 | Muji-Muji_Daruma | ORG | french |
| 172 | Vous | S-LOC | french |
| 173 | Sayu | S-PER | french |
| 174 | Anemo | S-PER | french |
5. 优化-识别语种并进行翻译
现在可以做到输入多语种文本输出其中有意义的实体和对应的实体类型与语言,那么遇到不懂的单词怎么办?于是有了优化需求:需要把实体词放在上下文语句中,并能翻译成中文进行辅助理解
翻译模块利用transformers中的MarianMTModel实现源语言到目标语言的翻译,在models中可看到其支持的语言对翻译模型,其中有英文到中文,德文到中文,不过缺乏法文到中文的模型
translate.py
from transformers import MarianTokenizer, MarianMTModel
def trans_lang(src,trg,sent):
"""
src:源语言
trg:目标语言
sent:输入语句
result:翻译语句列表,类型list
"""
model_name = f'Helsinki-NLP/opus-mt-{src}-{trg}'
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
batch = tokenizer([sent], return_tensors="pt")
gen = model.generate(**batch)
result = tokenizer.batch_decode(gen, skip_special_tokens=True)
print(result)
return result
将翻译模块与NER模块结合,就可以实现从混合语种的文本中输出有意义的实体词语并带有上下文语句及其翻译。这要是再有了Anki的加持,那绝对可以助力外语学习笔记系统的外循环了,既能了解时事,与时俱进,又能学习新单词,扩充词汇量,完美。
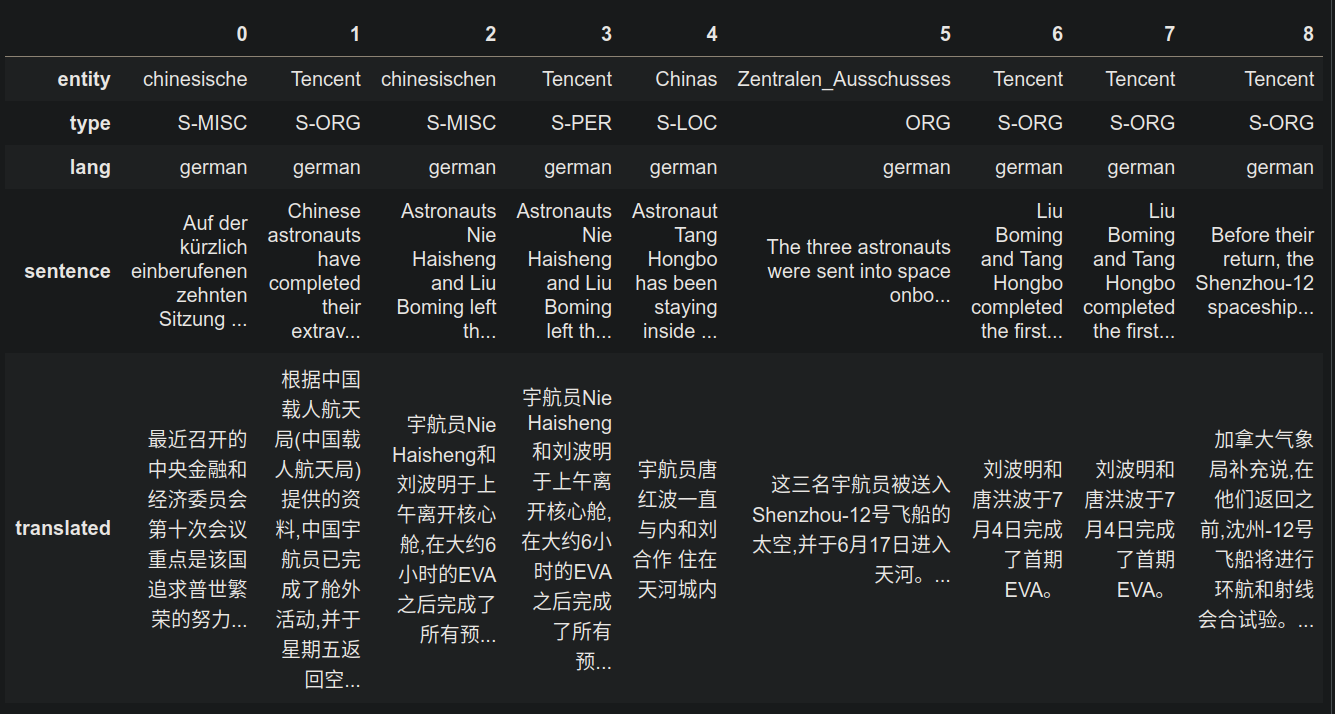
现用人民网中一篇德语新闻一篇英语新闻文本 de_en_news.txt进行测试,其数据来源为:
Tencent investiert in „Förderung des gemeinsamen Wohlstands“
Chinese astronauts complete second time EVAs for space station construction - People’s Daily Online
结果如下:
6. 小结
本文简要介绍了Trankit的优缺点、原理及其安装,并讨论实践Trankit应用到生活场景中在多语种新闻中进行命名实体识别,以实现个人信息过滤,借助transformers中的MarianMTModel实现自动识别语种并进行外语(德语、英语)到中文的翻译。
听说好像最后一句升华一下主题可能会吸引到更多关注,那就强行再补充一句感想:锤子(工具)与钉子(场景)左右手互搏可以带来产品的螺旋式迭代优化。