多语种命名实体识别的可视化版本
1.背景
上回写完基于Trankit的多语种命名实体识别之后,感觉整体效果只能算差强人意,要是能实现可视化,在原文中突显实体就更好了,就像上学时在课本里用彩笔划重点做笔记一样。当然了,笔者追求NER可视化效果,不只是为了什么情怀,什么颜值,还有一点是可以作为社畜提高生产力的生存小技巧[苦涩]:在工作中,老板领导们最喜欢看得见的东西,以结果为导向,看不见的结果那约等于是没结果。想实践出真知?不,在现实需要快速出结果的压力下,往往会变成实践出 demo,而如何优雅地进行NER是又快又好又美地出 demo的痛点之一。
本文主要围绕实现多语种NER可视化版本所进行的探索实践来展开讨论。
-
输入测试样例:
Der chinesische Technologieriese Tencent hat angekündigt, genau 50 Milliarden Yuan (6,6 Mrd. Euro) investieren zu wollen, um die Initiative für gemeinsamen Wohlstand der chinesischen Regierung zu fördern. Dies teilte das Unternehmen am Mittwoch über seinen offiziellen WeChat-Account mit. Astronauts Nie Haisheng and Liu Boming left the core module in the morning and completed all the scheduled tasks after approximately six hours of EVAs.数据来源:
人民网中一篇德语新闻一篇英语新闻混合文本 de_en_news.txt随机抽取出来的两段话
Tencent investiert in Förderung des gemeinsamen Wohlstands
Chinese astronauts complete second time EVAs for space station construction - People’s Daily Online
-
输出结果:在原文中高亮显示识别的实体
2. 探索spaCy
-
spaCy与可视化
spaCy 是可以做可视化的,详见 Visualizers · spaCy Usage Documentation
其中有专门做命名实体可视化的 demo(displaCy Named Entity Visualizer),可进行交互式测试,有实体标签类型可以进行勾选,不同类型实体用不同颜色进行标注展示,看着简洁美观醒目,不过有一点限制,必须要先选择好跟文本语种匹配的语言模型
-
spaCy与Multilingual
在Multi-language · spaCy Models Documentation中可以看到做 multilingual 的有xx_ent_wiki_sm 和 xx_sent_ud_sm,不过xx_sent_ud_sm 不能做 NER,且不支持中文
-
spaCy实践
-
安装
conda install -c conda-forge spacy==3.1.0 conda install -c conda-forge transformers在Releases · explosion/spacy-models · GitHub找到xx_ent_wiki_sm模型进行下载,然后进行安装
sudo pip3 install xx_ent_wiki_sm-3.1.0.tar.gzdisplacy可视化命名实体尝试
import spacy from spacy import displacy input_text = "Der chinesische Technologieriese Tencent hat angekündigt, genau 50 Milliarden Yuan (6,6 Mrd. Euro) investieren zu wollen, um die Initiative für gemeinsamen Wohlstand der chinesischen Regierung zu fördern. Dies teilte das Unternehmen am Mittwoch über seinen offiziellen WeChat-Account mit." nlp = spacy.load("xx_ent_wiki_sm") doc = nlp(text) displacy.serve(doc, style="ent")在网页
http://0.0.0.0:5000/中看到展示结果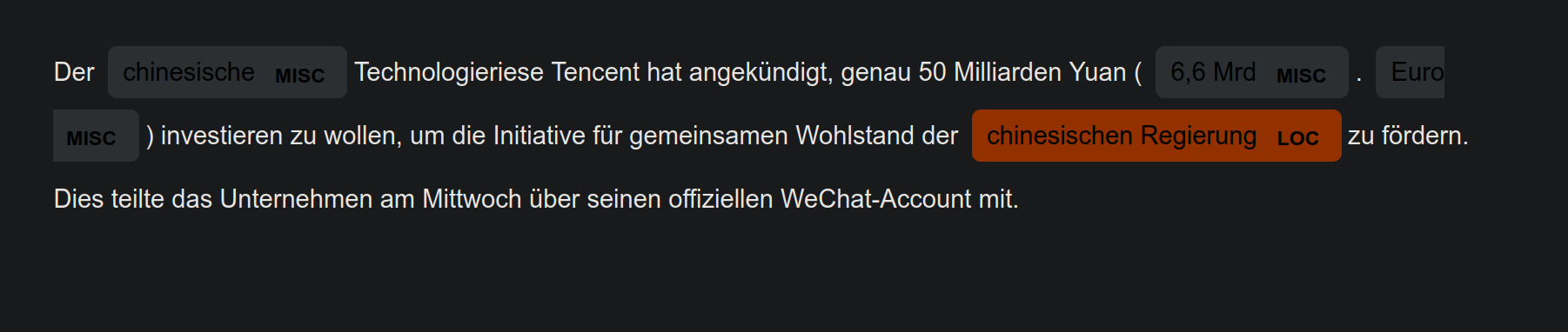
-
3. 探索T-NER
-
怎么知道T-NER的
一个偶然的机会在 Approach for training multilingual NER中看到有位答主建议道:
I suggest you take a look at the recent
tnerlibrary, which builds on top of Huggingface Transformers to make NER very easy.尤其是看到
make NER very easy于是我便神魂颠倒般服下这个安利开始尝试 T-NER -
T-NER是什么
T-NER是用pytorch实现的在NER进行语言模型微调的python工具,其背后的论文 T-NER: An All-Round Python Library for Transformer-based Named Entity Recognition - ACL Anthology已经被 EACL 2021 收录了
-
T-NER与可视化
所有经过 T-NER 微调的模型都可以被部署在 web 应用中进行可视化 (All models finetuned with T-NER can be deploy on our web app for visualization.) 看到这个就感觉很高级的样子,说话加个 all 就立马显得霸气十足,信心满满,迫不及待地想试试看
-
T-NER实践
-
安装
pip3 install tner遇到报错
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: '.../anaconda3/envs/t_ner/lib/python3.6/site-packages/numpy-1.19.5.dist-info/METADATA'解决
在python3.6/site-packages文件夹下看有没有numpy其他版本,比如我的看到除了有numpy-1.19.5.dist-info还有numpy-1.19.2.dist-info,发现在numpy-1.19.2. dist-info 文件夹下有 METADATA,于是复制到 numpy-1.19.5. dist-info 中去
-
开启 web app
git clone https://github.com/asahi417/tner cd tner然后开启 server 服务
uvicorn app:app --reload --log-level debug --host 0.0.0.0 --port 8000友情提示:在这个过程当中会下载 huggingface/transformers/中的一些数据模型,等待时间会比较长
当看到
INFO Application startup complete.时,就可以在网页http://0.0.0.0:8000上进行交互式的命名实体可视化测试了
这里的Max sequence length进度条最大可以调到512
输入稻妻wiki Inazuma中的一段文本
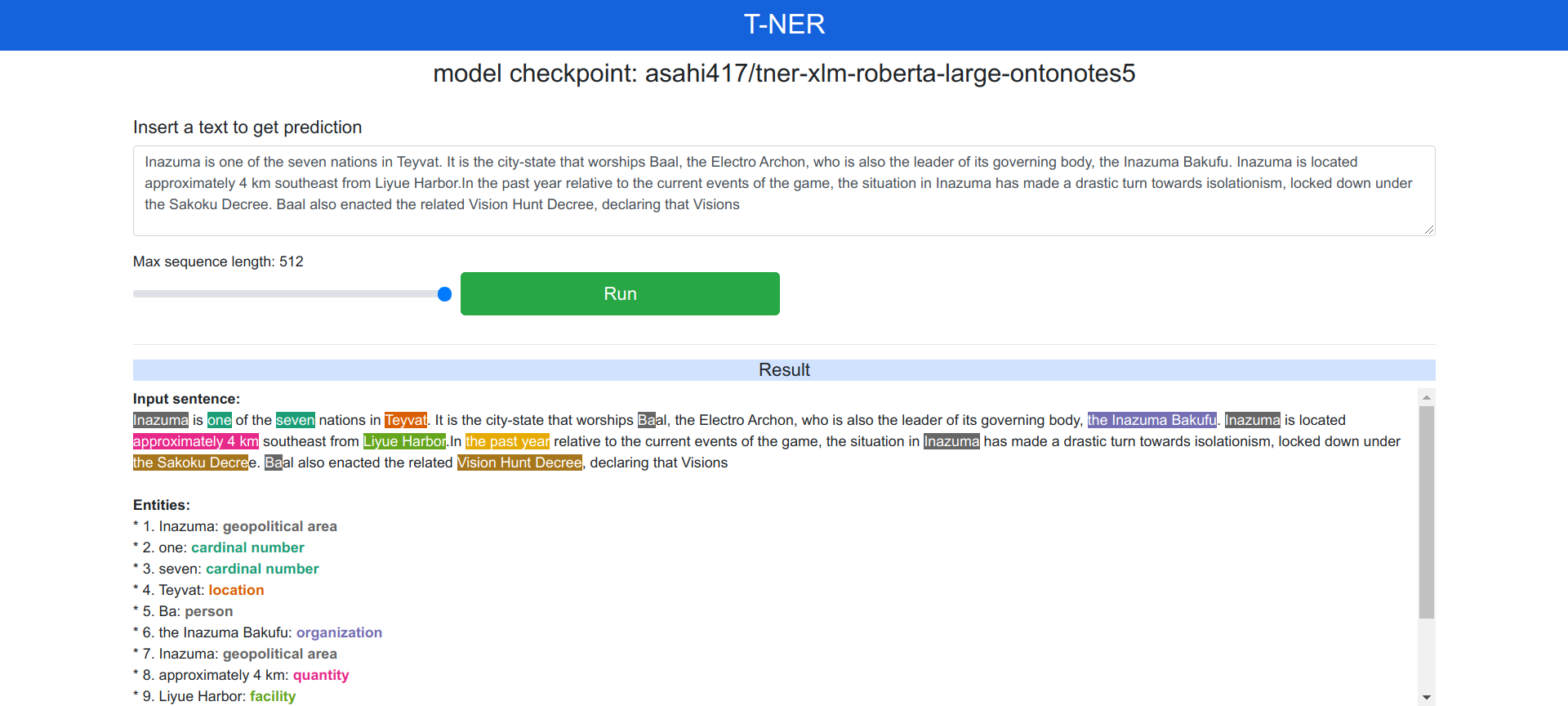
双语混合语言测试
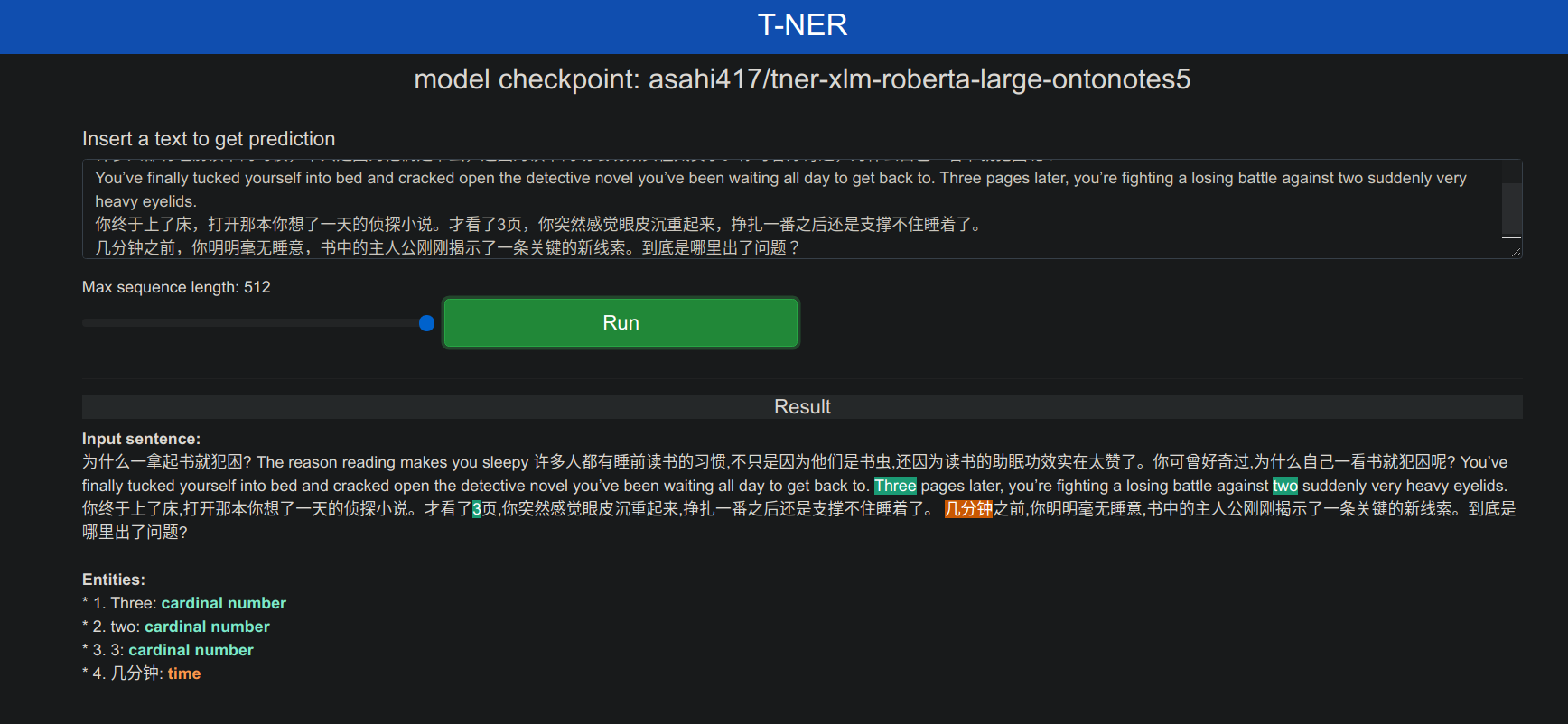
默认
NER_MODEL设置为asahi417/tner-xlm-roberta-large-ontonotes5,当然也可以在app.py修改NER_MODEL参数,选择配置特定的模型,在Models - Hugging Face中找到需要的模型。目前以 asahi417/tner 开头的模型有 46 个,可选数据集标明语言的有 all-english, ko, ru, en, ar, es, fin, ja可以在 Public datasets 和 Custom Dataset 上用 tner 训练模型,Public datasets 包括 OntoNotes 5 , CoNLL 2003, WNUT 2017, FIN (fin), BioNLP 2004, BioCreative V CDR, WikiAnn, Japanese Wikipedia , Japanese WikiNews , MIT Restaurant, MIT Movie 等数据集,大部分是英语和日语,还有 WikiAnn 数据集的 282 种语言;Custom Dataset 需要用 IOB 格式做命名实体识别的标注构造数据集
tner-xlm-roberta-large-ontonotes5模型可以支持多种语言,那就看一下法语的实体识别效果如何,从之前的原神早玉角色法语介绍 GenshinImpact.txt 中随机抽取一段文本进行测试

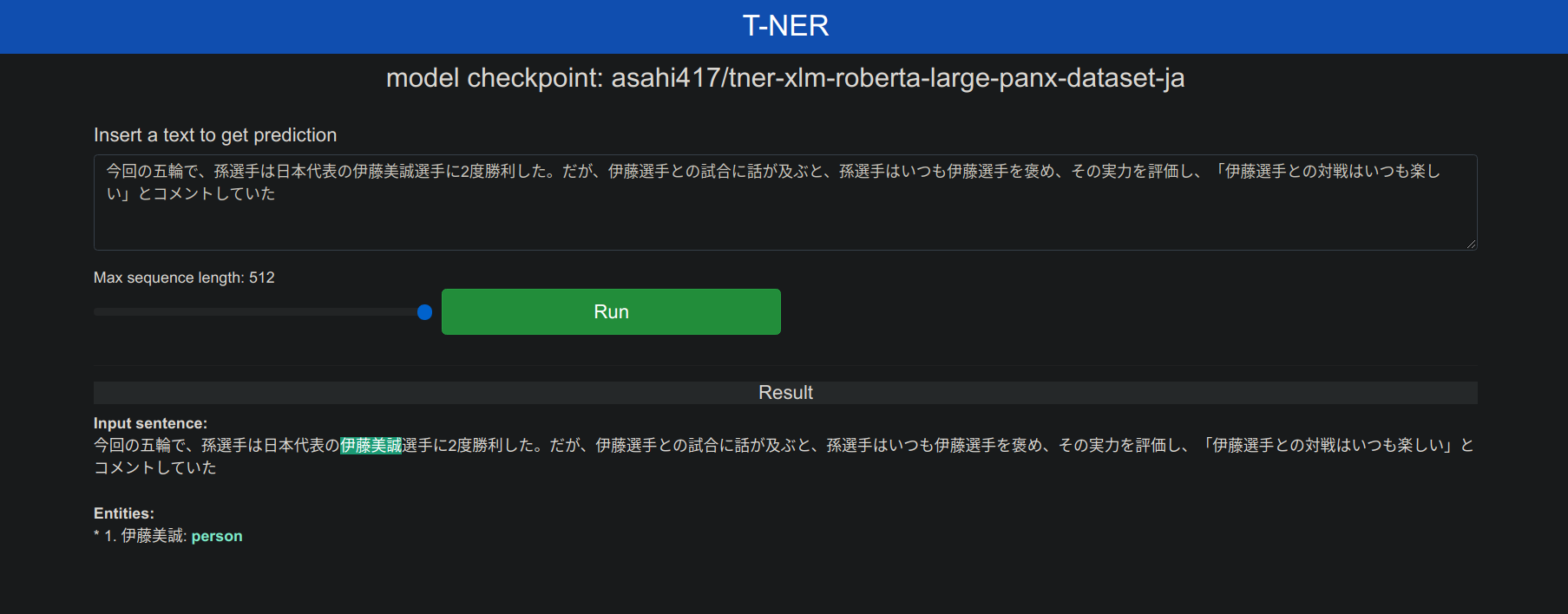
现在测试一下专用日语模型的实体识别效果
在app.py中将NER_MODEL那一行改为
NER_MODEL = os.getenv('NER_MODEL', 'asahi417/tner-xlm-roberta-large-panx-dataset-ja') 话说xlm-roberta真是yyds
测试文本数据来源 卓球・孫穎莎選手、五輪の自己採点は「80-85点」–人民網日本語版–人民日報
-
-
T-NER论文笔记
-
spaCy不适合在任意NER数据中进行语言模型的微调或者评测(笔者:那T-NER就适合?)
Although it provides a very efficient pipeline for processing text, it is not suitable for LM finetuning or evaluation on arbitrary NER data.
-
T-NER可以进行跨领域的分析研究,这是亮点
Most notably, it enables to organize cross-domain analyses such as training a NER model and testing it on a different domain, with a small configuration.
-
前文提到所有经过 T-NER 微调的模型都可以直接部署可视化,笔者在想,那保证动态发展变化的新模型不会翻车?看了论文才知道,T-NER跟Transformer hub有个梦幻联动,可以直接从Transformers的模型用到T-NER中来
Our library is therefore fully compatible with the Transformers framework: once new model was deployed on the Transformer hub, one can immediately try those models out with our library as a NER model.
-
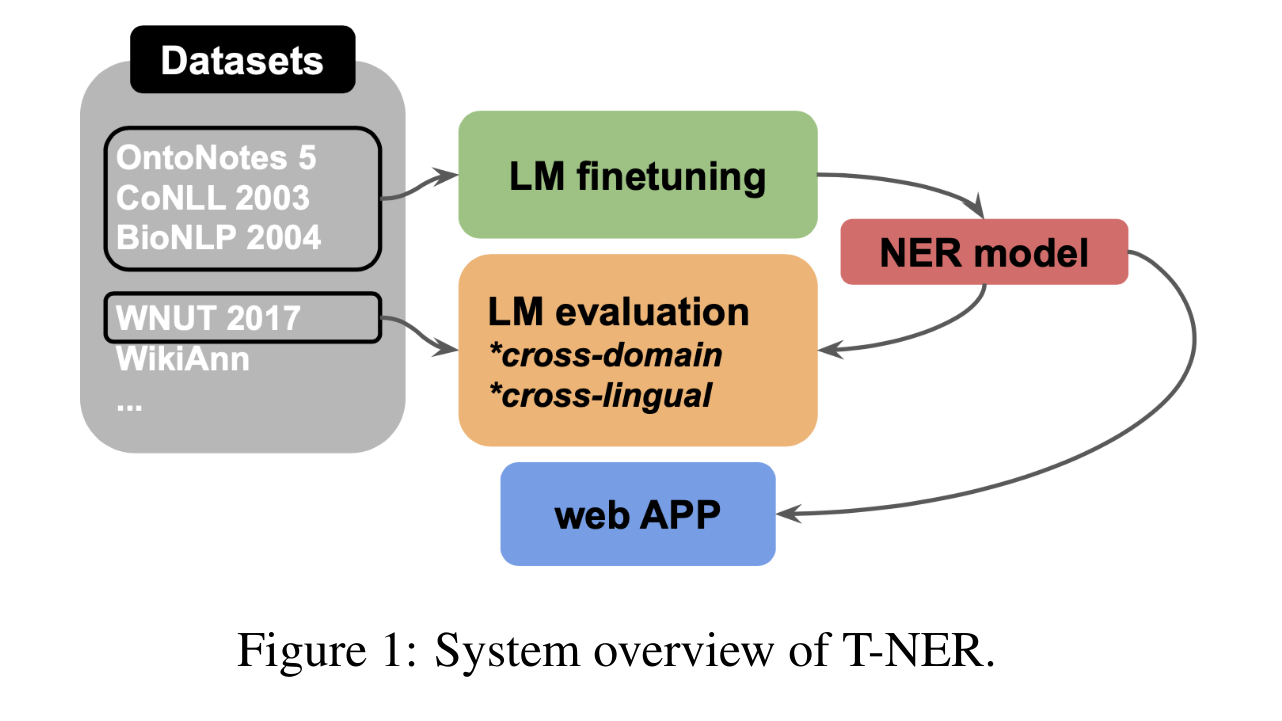
整体流程
-
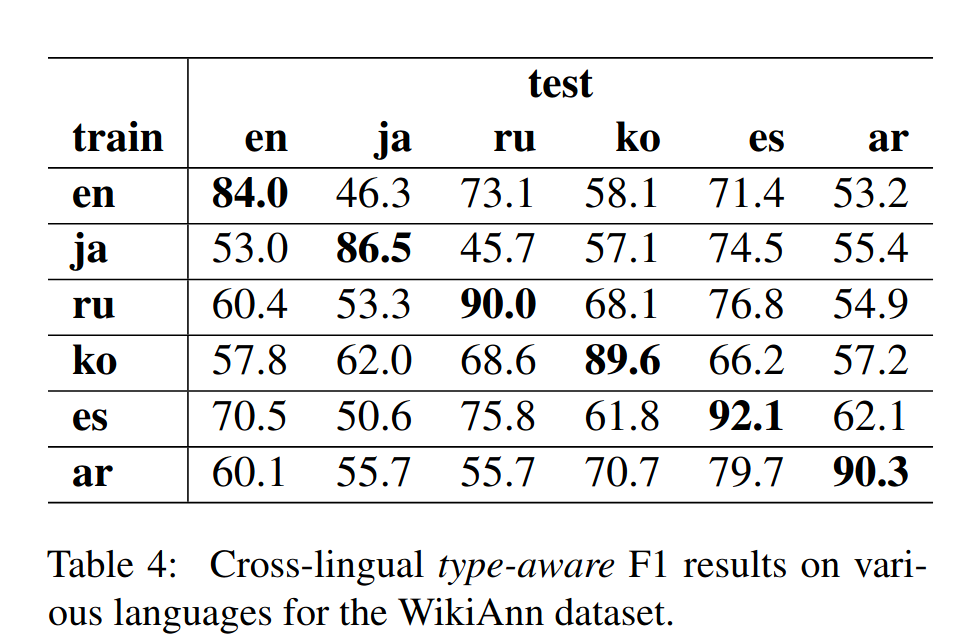
在WikiAnn数据集中测试跨语言
Finally, we present some results for zero-shot cross-lingual NER over the WikiAnn dataset, where we include six distinct languages: English (en),Japanese (ja), Russian (ru), Korean (ko), Spanish(es), and Arabic (ar). In Table 4, we show the cross-lingual evaluation results. The diagonal includes the results of the model trained on the training data of the same target language. There are a few interesting findings. First, we observe a high correlation between Russian and Spanish, which are generally considered to be distant languages and do not share the alphabet. Second, Arabic also transfers well to Spanish which, despite the Arabic (lexical) influence on the Spanish language (Stewart et al., 1999),are still languages from distant families.
-
4. 测试spaCy,T-NER与trankit的NER效果
spaCy,T-NER,trankit这三个都可以进行多语种的命名实体识别,所以想看看输入同样一段双语混合文本,它们的NER结果会有什么样的不同,进行比较一下
现让spaCy用xx_ent_wiki_sm模型,让T-NER用asahi417/tner-xlm-roberta-large-ontonotes5模型,trankit用的是XLM-Roberta Base,一起同台竞技一下
- ner_compare.py
from tner import TransformersNER
import os
from trankit import Pipeline
import spacy
import pandas as pd
from pandas.core.frame import DataFrame
#frame输出完整
pd.options.display.max_rows = None
#frame输出对齐
pd.set_option('display.unicode.ambiguous_as_wide',True) # 将模糊字符宽度设置为2
pd.set_option('display.unicode.east_asian_width',True) # 检查东亚字符宽度属性
#设置显示的长宽
pd.set_option('display.height',1000)
pd.set_option('display.max_rows',500)
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
def tner_text(input_text,max_len=512):
NER_MODEL = os.getenv('NER_MODEL', 'asahi417/tner-xlm-roberta-large-ontonotes5')
MODEL = TransformersNER(NER_MODEL)
tner_result = MODEL.predict([input_text], max_seq_length=max_len)[0]
ner_list = []
ner_type = []
ner_span = []
for term in tner_result["entity"]:
ner_list.append(term["mention"])
ner_type.append(term["type"])
ner_span.append(term["position"])
ner_dict = {"entity":ner_list,"type":ner_type,"position":ner_span}
ner_frame = DataFrame.from_dict(ner_dict,orient='index')
return ner_frame
def trankit_text(input_text):
p = Pipeline('english',gpu=True)
p.add('chinese')
p.add('french')
p.add('german')
p.set_auto(True)
ner_unite = []
ner_single = []
ner_type = []
ner_span = []
ner_output = p.ner(input_text)
sent = ner_output['sentences']
#print(sent)
#sent_lang表示语种识别的语言名称
sent_lang = ner_output['lang']
for sent_part in sent:
tokens_info = sent_part['tokens']
sent_text = sent_part['text']
BIE_token = []
for token in tokens_info:
#"O"表示不属于任何实体类型,是无意义的,需要过滤掉
if token['ner'] != "O":
#合并NER的开始、中间、结束
if 'B-' in token['ner']:
ner_unite.append(token['text'])
BIE_token.append(token["dspan"][0])
continue
elif 'I-' in token['ner']:
#print(token['ner'])
ner_unite.append(token['text'])
continue
elif 'E-' in token['ner']:
ner_unite.append(token['text'])
#print(ner_unite)
BIE_token.append(token["dspan"][1])
ner_span.append(BIE_token)
BIE_token = []
if sent_lang == "chinese":
ner_single.append(''.join(ner_unite))
else:
#当遇到非中文语言时用' '将分割的NER部分相连,不然会影响阅读,印欧语系中的语言以表音构成,用空格来区分单词
ner_single.append(' '.join(ner_unite))
ner_type.append(token['ner'].replace("E-", ""))
ner_unite = []
else:
#其他情况表示NER部分没有被分割掉,可单独成实体
ner_single.append(token['text'])
ner_type.append(token['ner'])
ner_span.append([token["dspan"][0],token["dspan"][1]])
ner_dict = {"entity":ner_single,"type":ner_type,"position":ner_span}
ner_frame = DataFrame.from_dict(ner_dict,orient='index')
return ner_frame
def spacy_text(input_text):
nlp = spacy.load("xx_ent_wiki_sm")
doc = nlp(input_text)
ner_list = []
ner_type = []
ner_span = []
for term in doc.ents:
ner_list.append(term.text)
ner_type.append(term.label_)
ner_span.append([term.start_char,term.end_char])
ner_dict = {"entity":ner_list,"type":ner_type,"position":ner_span}
ner_frame = DataFrame.from_dict(ner_dict,orient='index')
return ner_frame
if __name__ == '__main__':
input_text = "Der chinesische Technologieriese Tencent hat angekündigt, genau 50 Milliarden Yuan (6,6 Mrd. Euro) investieren zu wollen, um die Initiative für gemeinsamen Wohlstand der chinesischen Regierung zu fördern. Dies teilte das Unternehmen am Mittwoch über seinen offiziellen WeChat-Account mit.Astronauts Nie Haisheng and Liu Boming left the core module in the morning and completed all the scheduled tasks after approximately six hours of EVAs."
spacy_result = spacy_text(input_text)
tner_result = tner_text(input_text)
trankit_result = trankit_text(input_text)
print("="*40+"input text"+"="*40)
print(input_text)
print("="*40+"spacy ner result"+"="*40)
print(spacy_result)
print("="*40+"tner result"+"="*40)
print(tner_result)
print("="*40+"trankit result"+"="*40)
print(trankit_result)
-
输出结果
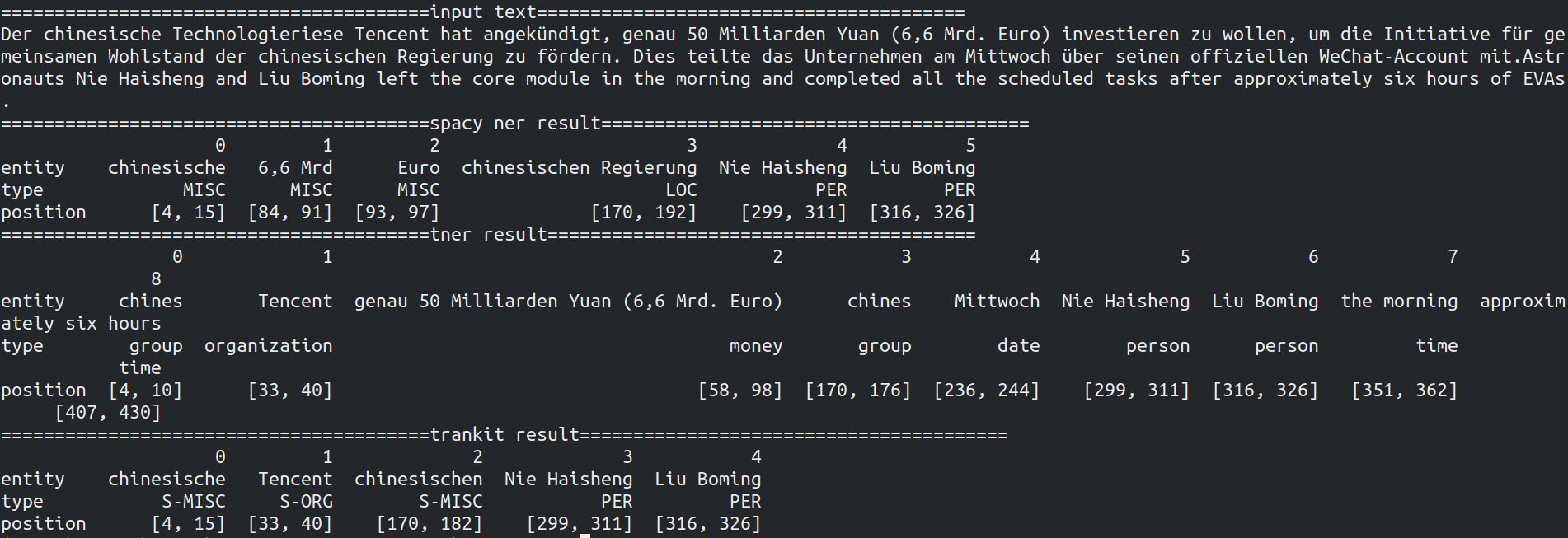
-
分析
T-NER识别的种类比较多,不过存在实体切断和误判类型;spaCy是比较稳的,不愧为工业级落地应用工具;trankit识别出的实体较少,求准为上。
正当笔者想要拿更多样例进行测试去比较这三个孰优孰劣时,等等,发现好像哪里有点不对劲。明明是想实现多语种NER的可视化,为什么要纠结哪个工具更完美?挑起对立不是笔者所擅长的,还是别走偏了,专注于实现真正的目标吧。分清楚谁是我们的朋友,谁是我们的敌人。秉持着「孩子才做选择,成年人全都要」的原则,与其让工具模型们窝里横,不如让它们联合起来一起解决问题,接下来朝可视化目标前进。
5. NER的联合与可视化
spaCy中的displacy可以用手工的形式进行定制可视化实体,需要实体的起止位置和标签
现在已经有了NER的实体类型和实体边界,可视化就好说了,万事俱备,哈哈如此说来边界感的确很重要,不管是词与词之间,还是人与人之间[手动狗头]
ner_displacy.py
from spacy import displacy
from ner_compare import spacy_text,trankit_text,tner_text
input_text = "Der chinesische Technologieriese Tencent hat angekündigt, genau 50 Milliarden Yuan (6,6 Mrd. Euro) investieren zu wollen, um die Initiative für gemeinsamen Wohlstand der chinesischen Regierung zu fördern. Dies teilte das Unternehmen am Mittwoch über seinen offiziellen WeChat-Account mit.Astronauts Nie Haisheng and Liu Boming left the core module in the morning and completed all the scheduled tasks after approximately six hours of EVAs."
spacy_result = spacy_text(input_text)
tner_result = tner_text(input_text)
trankit_result = trankit_text(input_text)
ent_list = []
for term in [spacy_result,tner_result,trankit_result]:
for (columnName, columnData) in term.iteritems():
ent_dict = {}
ent_dict["start"] = columnData.values[2][0]
ent_dict["end"] = columnData.values[2][1]
ent_dict["label"] = columnData.values[1]
ent_list.append(ent_dict)
doc = {
"text": input_text,
"ents": ent_list,
"title": "spaCy & T-NER & trankit"
}
displacy.serve(doc, style="ent" ,manual=True)
结果如下:
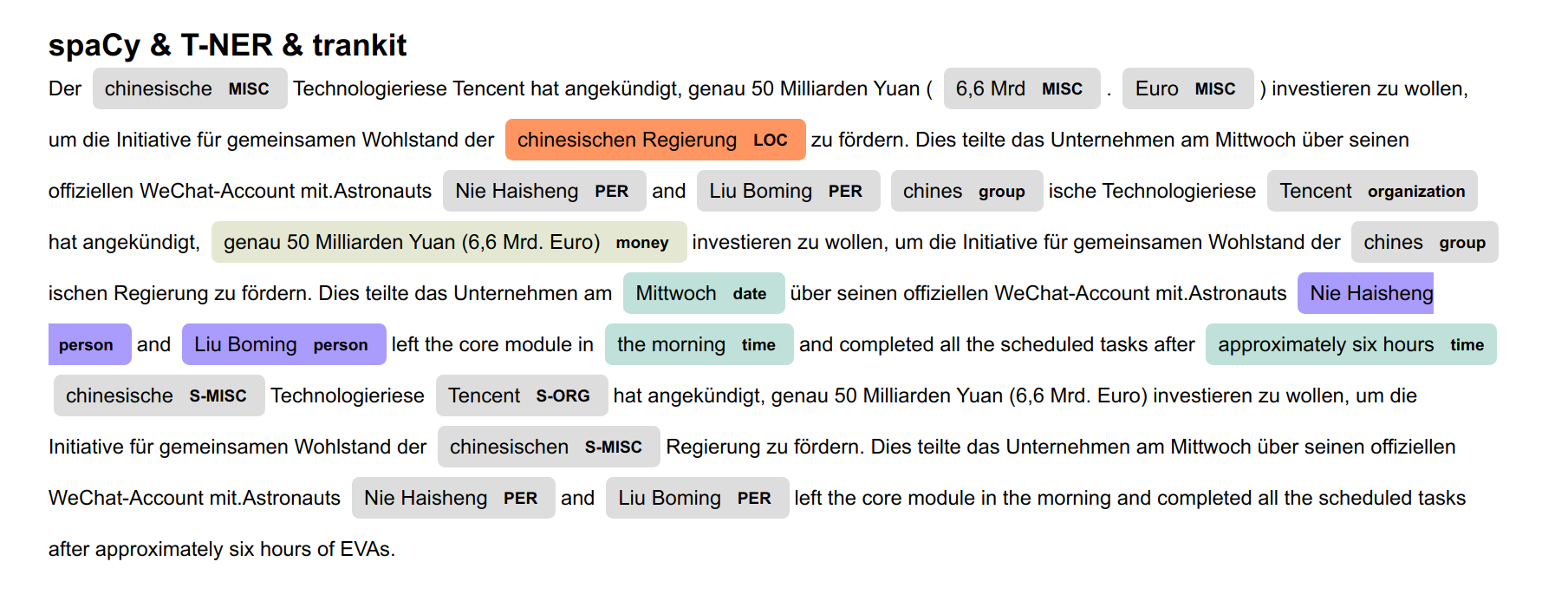
6. 小结
本文为了实现多语种命名实体识别的可视化而做了一些尝试和实践,顺便测试并比较了spaCy,T-NER与trankit的命名实体识别效果,最后联合这三者对识别的实体进行汇总,借助spaCy的displacy进行可视化展示,可用不同颜色高亮识别的实体并标注相应实体类型。
哈哈最后引用一句鸡汤: “不要因为走得太远而忘记为什么出发”